关于KMP
KMP其实是三个人名字的缩写,因为是他们同时发现的(大佬惹不起);
KMP作为CSP考点,主要亮点是其优秀的匹配复杂度,而且消耗空间小,比起hash虽然有些局限性,但是因为其正确率高,所以经常被人使用.
前置知识
关于字符串的读取,以及字符串相关操作的基础了解,这里涉及字符串匹配以及子串;
差分,也就是数与数之间的差值。拿一维差分来举例子,将差分设为c[ ]数组,原数为a[ ],那么
$c[i]=a[i]-a[i-1]$
这便是简单的差分数组;
那么要他何用?
最为主要的作用就是区间的修改,那么在修改之前,我们先明白如何将原数求出。很显然,$c[1]$~$c[i]$差分数组求和即可得到$a[i]$。
请在学习之前有一定的线段树基础
在一些题中,它总会给你一些矩形,之后让你求总覆盖面积。
它的难点在于,有重叠面积,如果只是罗列情况,那么只会一事无成。
所以说,这里就引进了扫描线做法;
其实它的原理很简单,只是底*高而已,只是分段求解;
而问题大概的图就是这样
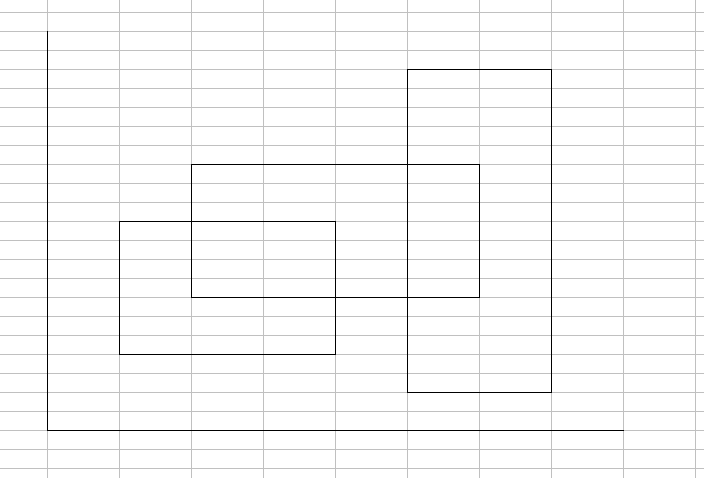
根据我刚刚说的分段求解和底*高,那么我们就可以推测出扫描线是什么了
。。。。
有点懒;
需要先理解几个概念:
LCA
线段树(熟练,要不代码能调一天)
图论的基本知识(dfs序的性质)
这大概就好了;
定义:
1.重儿子:一个点所连点树size最大的,这个son被称为这个点的重儿子;
2.轻儿子:一个点所连点除重儿子以外的都是轻儿子;
3.重链:从一个轻儿子或根节点开始沿重儿子走所成的链;
manacher算法的由来不再赘述,自行百度QWQ。。。
进入正题,manacher算法是一个高效的计算回文串的算法,回文串如果不知道可以给出一个例子:“ noon ”,这样应该就很清晰了;
其实这个算法虽然名字长,但是实际代码很短,而且理解起来并不难。。。(连我这种蒟蒻都懂了)
这里给出模板题
给出一个只由小写英文字符a,b,c…y,z组成的字符串S,求S中最长回文串的长度.
先存代码
1 |
|